Official PyTorch implementation for FuXi-beta: Towards a Lightweight and Fast Large-Scale Generative Recommendation Model.
![]()
1. Paper
Yufei Ye, Wei Guo, Hao Wang, Hong Zhu, Yuyang Ye, Yong Liu, Huifeng Guo, Ruiming Tang, Defu Lian, and Enhong Chen. FuXi-beta: Towards a Lightweight and Fast Large-Scale Generative Recommendation Model. arXiv preprint arXiv:2508.10615, 2025.
Paper / PDF / Project Page / Citation
FuXi-beta studies efficiency bottlenecks in large-scale generative recommendation models and proposes a lightweight design for faster training and inference. The repository provides the PyTorch implementation and public MovieLens experiment configs.
2. Highlights
- Targets training and inference efficiency for large-scale generative recommendation.
- Builds on FuXi-alpha and HSTU-style sequential recommendation components.
- Introduces lightweight attention/bias handling in the FuXi-beta sequential encoder.
- Provides public MovieLens configs for reproducible experiments.
3. Method At A Glance
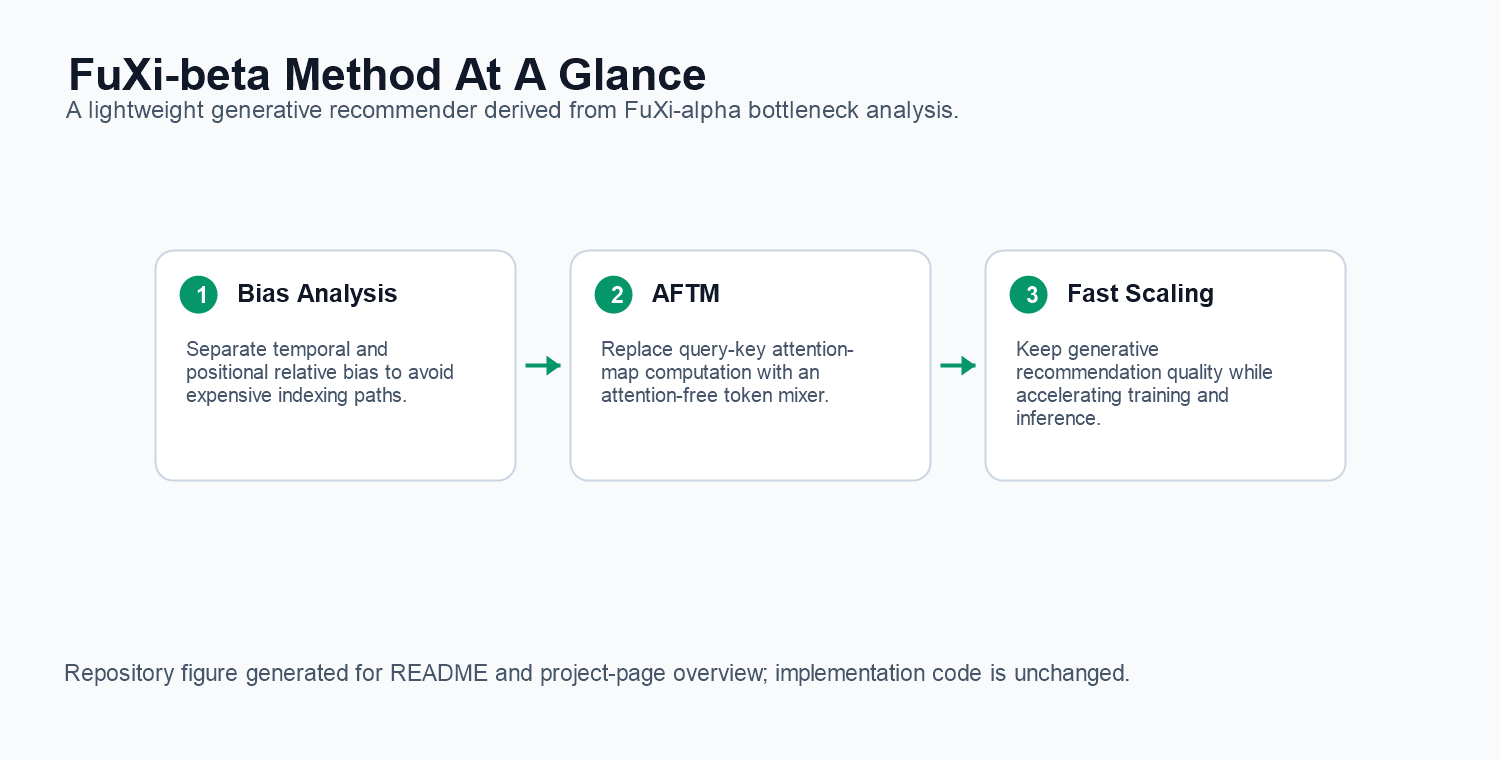
FuXi-beta analyzes bottlenecks from relative temporal attention bias and query-key attention-map computation, then replaces expensive operations with a lightweight token-mixing path.
4. Repository Structure
.
├── configs/ # MovieLens experiment configs
├── generative_recommenders/modeling/sequential/ # FuXi-beta and baseline encoders
├── generative_recommenders/trainer/ # Training pipeline
├── main.py # Distributed training entry
├── preprocess_public_data.py # MovieLens preprocessing
├── requirements.txt
└── docs/ # GitHub Pages project pageThe FuXi-beta model code is under generative_recommenders/modeling/sequential/fuxi_beta.py.
5. Installation
Install PyTorch following the official instructions for your CUDA environment, then install dependencies:
pip install -r requirements.txtThe original quick setup used:
pip3 install gin-config absl-py scikit-learn scipy matplotlib numpy apex hypothesis pandas fbgemm_gpu iopath6. Data
Prepare the public MovieLens data:
mkdir -p tmp/
python3 preprocess_public_data.py7. Quick Start
Run FuXi-beta on MovieLens-1M:
CUDA_VISIBLE_DEVICES=0 python3 main.py \
--gin_config_file=configs/ml-1m/fuxi-beta-sampled-softmax-n128-final.gin \
--master_port=12345Other configurations are included in configs/ml-1m/ and configs/ml-20m/.
8. Reproducing Results
A GPU with 24GB or more HBM should work for most public MovieLens settings.
Training logs are written to exps/ by default. Launch TensorBoard with:
tensorboard --logdir ~/generative-recommenders/exps/ml-1m-l200/ --port 24001 --bind_all
tensorboard --logdir ~/generative-recommenders/exps/ml-20m-l200/ --port 24001 --bind_all9. Configuration Notes
configs/ml-1m/fuxi-beta-sampled-softmax-n128-final.gin: default MovieLens-1M FuXi-beta setting.configs/ml-20m/fuxi-beta-sampled-softmax-n128-final.gin: default MovieLens-20M FuXi-beta setting.- Baseline configs for FuXi-alpha, HSTU, SASRec, and FLASH are included for comparison.
10. Experimental Highlights
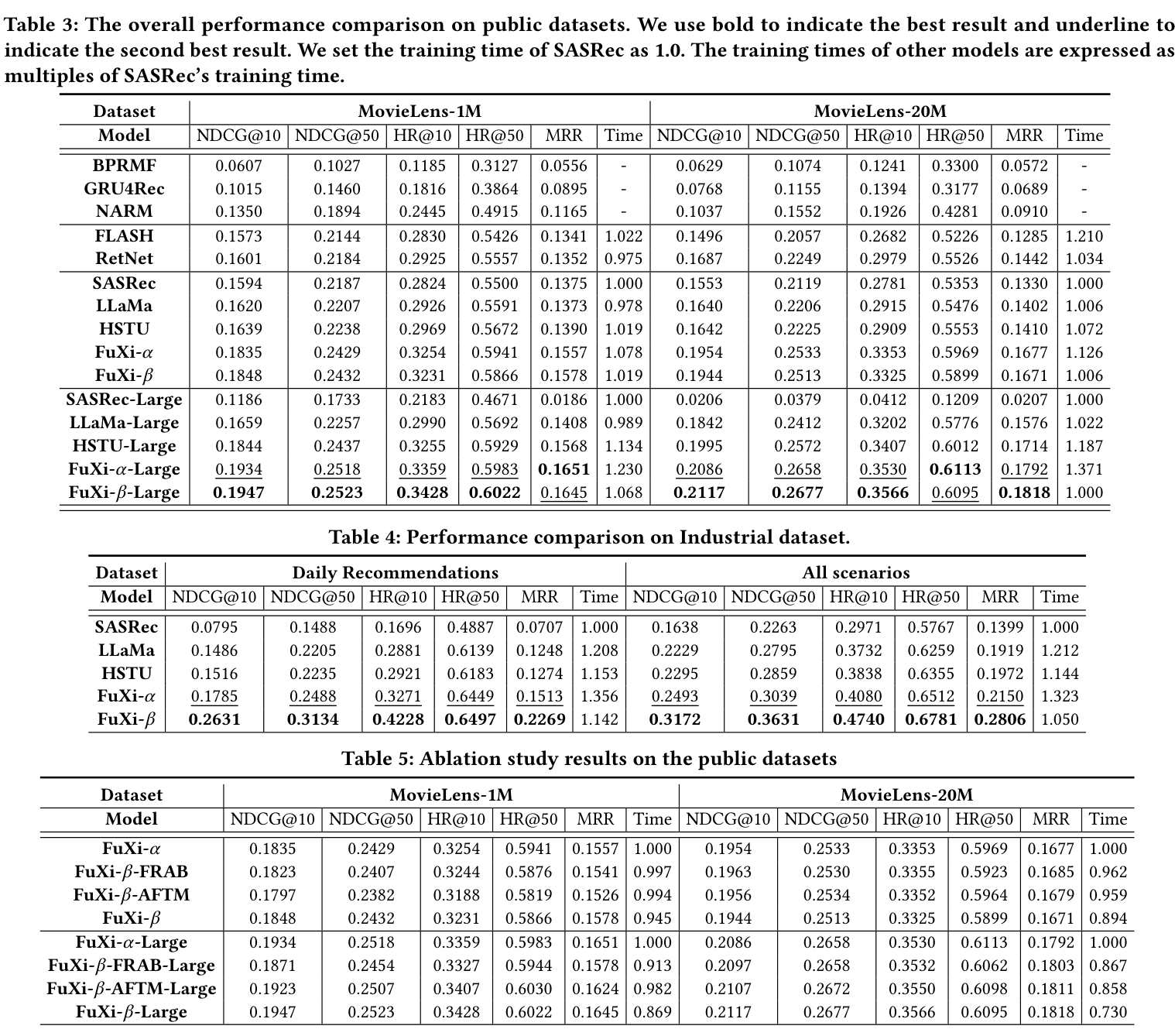
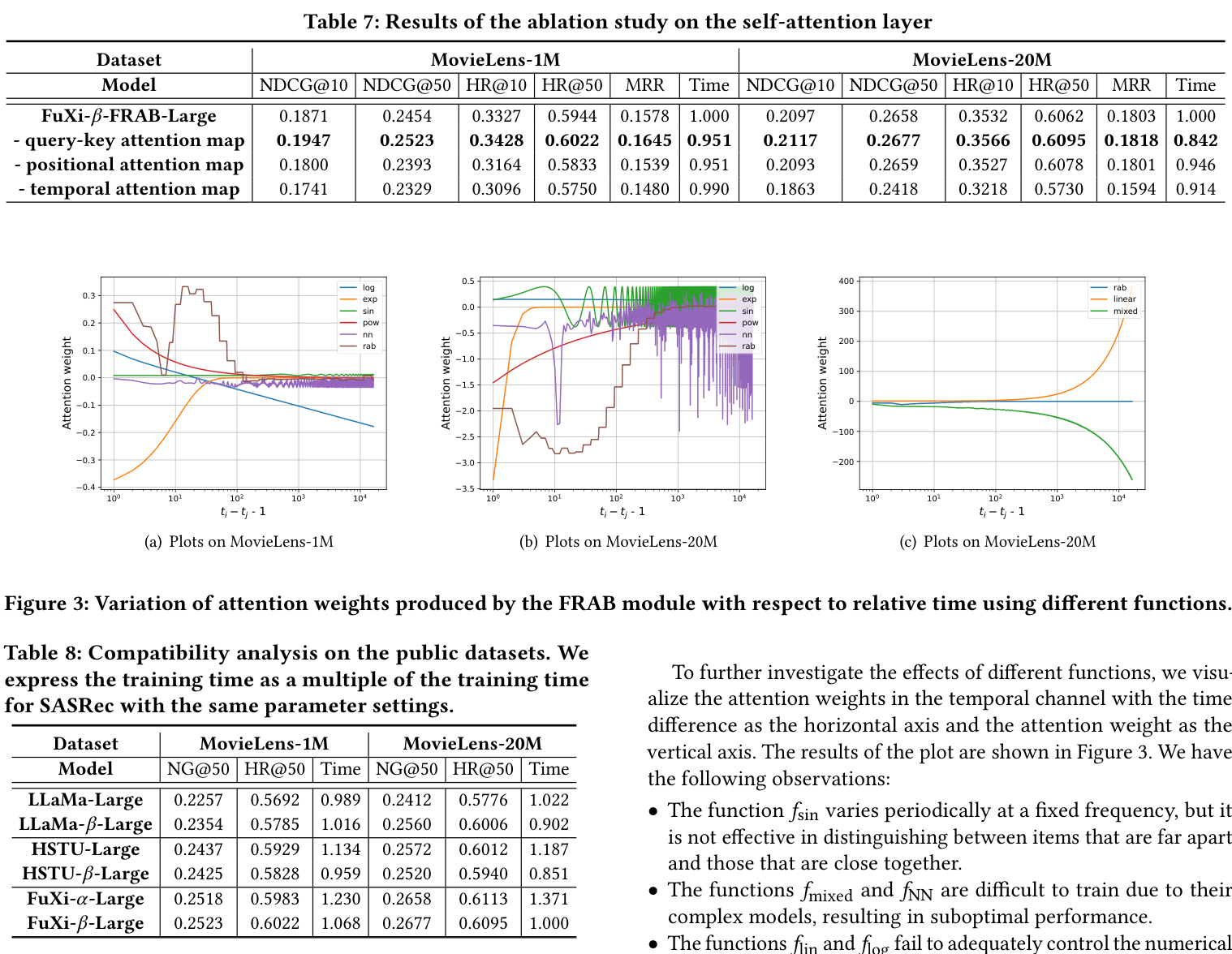
The paper tables above make the lightweight accuracy-cost tradeoff visible: FuXi-beta is compared with FuXi-alpha/HSTU/SASRec variants, then analyzed through attention and compatibility ablations.
FuXi-beta is positioned as a lightweight successor to heavier generative recommendation models. The code includes both FuXi-alpha and FuXi-beta components for direct architectural comparison.
| Finding | Paper evidence | Takeaway |
|---|---|---|
| Industrial accuracy | On large-scale industrial datasets, FuXi-beta reports +27% to +47% NDCG@10 compared with FuXi-alpha. | The lightweight design is not only an efficiency change. |
| Public benchmark behavior | The paper reports performance comparable to prior state of the art on public datasets while significantly reducing training time. | FuXi-beta targets a better accuracy-cost balance. |
| Query-key attention ablation | Removing the query-key attention map improves MovieLens-1M NDCG@10 from 0.1871 to 0.1947 and reduces relative time from 1.000 to 0.951; on MovieLens-20M, NDCG@10 moves from 0.2097 to 0.2117 and time from 1.000 to 0.842. | The paper's efficiency claim is tied to a concrete architectural simplification. |
| Temporal attention ablation | Removing temporal attention hurts MovieLens-20M NDCG@10 from 0.2097 to 0.1863. | The lightweight model still depends on explicit temporal information. |
Conclusion: FuXi-beta keeps the useful temporal structure from FuXi-alpha while removing expensive attention components that are less helpful for recommendation.
11. Notes For Maintainers
- Keep
fuxi_beta.pyand thefuxi-beta-*config names stable because README commands depend on them. - If new benchmark configs are added, mirror them in both the README and project page.
- Do not change preprocessing assumptions without verifying compatibility with the existing MovieLens configs.
12. Citation
If you find FuXi-beta useful, please cite:
@article{ye2025fuxibeta,
title={FuXi-beta: Towards a Lightweight and Fast Large-Scale Generative Recommendation Model},
author={Ye, Yufei and Guo, Wei and Wang, Hao and Zhu, Hong and Ye, Yuyang and Liu, Yong and Guo, Huifeng and Tang, Ruiming and Lian, Defu and Chen, Enhong},
journal={arXiv preprint arXiv:2508.10615},
year={2025}
}13. Contact
- First author: Yufei Ye (
aboluo2003@mail.ustc.edu.cn). - Corresponding authors: Hao Wang (
wanghao3@ustc.edu.cn), Yong Liu (liu.yong6@huawei.com), Defu Lian (liandefu@ustc.edu.cn), and Enhong Chen (cheneh@ustc.edu.cn). - Repository questions: please open a GitHub issue in this repository.